 2025.10.30
2025.10.30
こんにちは。
今回は、直近で試験的に構築したレコメンデーション機能の仕組みと実装の工夫についてご紹介します。
ユーザーの行動データから「この人が次に興味を持ちそうなアイテム」を見つける仕組みです。
🧠 そもそも「アイテムベース協調フィルタリング」とは?
レコメンデーションにはさまざまなアプローチがありますが、今回採用したのは
アイテムベース協調フィルタリング(Item-Based Collaborative Filtering, IBCF)。
シンプルながら、計算効率・説明のしやすさ・実運用での安定性という点で非常に優れています。
🔍 基本の考え方
ロジックはいたってシンプルです。
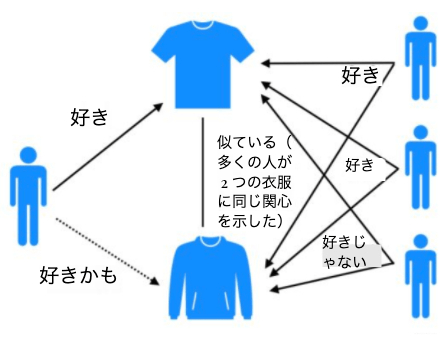
「ユーザーAが好んだアイテムと似ているアイテムは、今後も好まれる可能性が高い」
つまり、“似ているアイテム同士”の関係性に注目する点がポイント。
ユーザー間の関係を追う「ユーザーベース」と違い、アイテムを中心に考えるアプローチです。
💡 なぜこの手法を選んだのか?
1. スケーラブルで軽い!
ユーザー数が増えても、計算対象は「アイテム間の関係」に限定されるため、処理コストを抑えつつ拡張が容易です。
2. 新規ユーザー・新規アイテムにも柔軟
人気アイテムや属性情報を使うことで、データが少ない段階でも一定の推薦が可能です。
3. ビジネス説明がしやすい
「あなたが好きな商品Xに似た商品Yをおすすめしています」
── こうしたわかりやすい説明ができるのは大きな強みです。
4. 更新が速い
ユーザー行動の変化にリアルタイムで追随しやすく、オンライン学習とも相性抜群です。
🧭 レコメンデーション機能の実装解説
🧩 ステップ1:イベント重要度を考慮した重み付け
ユーザーの行動はすべてが同じ価値を持つわけではありません。
例えば「購入」は「閲覧」よりも重要です。
そこで、イベントタイプごとに異なる重みを設定しました。
# イベントタイプごとに異なる重みを設定
EVENT_WEIGHTS = {
'purchase': 10.0,
'add_to_cart': 5.0,
'page_view': 1.0
}
# 学習データにイベント重みを付与
df_train['event_weight'] = df_train['event_name'].map(EVENT_WEIGHTS)
⚖️ ステップ2:ユーザーごとのスケール調整と相対的重要度の強調
# Min-Max正規化:ユーザーごとに [0,1] に揃える
df_agg['min_weight'] = df_agg.groupby('user_id')['event_weight'].transform('min')
df_agg['max_weight'] = df_agg.groupby('user_id')['event_weight'].transform('max')
df_agg['weight'] = (df_agg['event_weight'] - df_agg['min_weight']) / \
(df_agg['max_weight'] - df_agg['min_weight']).replace(0, 1)
# 中心化:平均を0に調整
df_agg['mean_weight'] = df_agg.groupby('user_id')['weight'].transform('mean')
df_agg['weight'] = df_agg['weight'] - df_agg['mean_weight']
df_agg['weight'] = df_agg['weight'].clip(lower=0)
df_agg:推薦モデルへの入力データ。ユーザー × アイテム × 重み(行動の重要度)の構造を持つ。
この処理の意図は次の通りです。
- 正規化により、行動規模の異なるユーザー間でも公平な比較が可能に
- 中心化で「活動量の差」を打ち消し、相対的な好みの傾向だけを抽出
- クリッピングで過度なペナルティを防ぎ、ノイズを抑制
これにより、「エンゲージメントの強いユーザー」と「ライトユーザー」の双方で、バランスよく相似度が算出されるようになりました。
🏗️ ステップ3:ユーザー×アイテムマトリックスと相似度行列の構築
次に、ユーザーの行動データを基に、ユーザー×アイテムマトリックスを作成します。
これを使ってアイテム間の類似度(相似度)をコサイン類似度で算出します。
# ユーザー・アイテムをインデックス化してマトリックスを構築
user_store_matrix = build_weighted_matrix(df_train, kappa=KAPPA)
similarity_matrix = build_store_similarity_matrix(user_item_matrix, df_train, item_encoder)
同じユーザーに好まれているアイテムほど高い相似度を持ち、
結果として「似た顧客層を惹きつけるアイテム同士」が自然にグルーピングされます。
※build_weighted_matrix:ユーザー×アイテムの重み付き行列を構築する関数
build_store_similarity_matrix:コサイン類似度によって、アイテム同士の類似度を評価値行列から計算する関数
🎯 ステップ4:推薦スコアの計算
最後に、ユーザーがまだ訪問していないアイテムを候補として、推薦スコアを算出します。
# ユーザーが未接触のアイテムのみを対象に
candidate_items = all_items - user_visited_items
# 接触済みアイテムとの相似度の加重平均をスコアに
recommendation_iteme = similarity_matrix[visited_items] @ user_weights
この構造は非常にシンプルですが、
その分高速かつ解釈しやすいというのがアイテムベース協調フィルタリングの大きな利点です。
「なぜこのアイテム舗が推薦されたのか?」をビジネスサイドに説明しやすいのも魅力です。
💡 実装を通じて得た知見
正規化と中心化の順序が重要
順序を変えるだけで推薦精度が大きく変わることを確認しました。
今回のように“個別調整 → ノイズ除去”の順序が安定的でした。
スパースな領域でもロバスト
新規ユーザーのようにデータが少ないケースでも、
ユーザー単位でのスケーリングにより、一定の信頼性を維持できます。




